Sometimes it’s not enough for something to work - it has to work under load. In modern applications that process large amounts of data, the Streams API in Java provides developers with an elegant, declarative tool to transform, filter, and aggregate data in pipelines. Describing complex data operations with just a few lines is seductive and realistic. But what happens when these operations encounter millions of entries? When should execution be done in multiple threads in parallel to save time and effectively use multi-core systems?
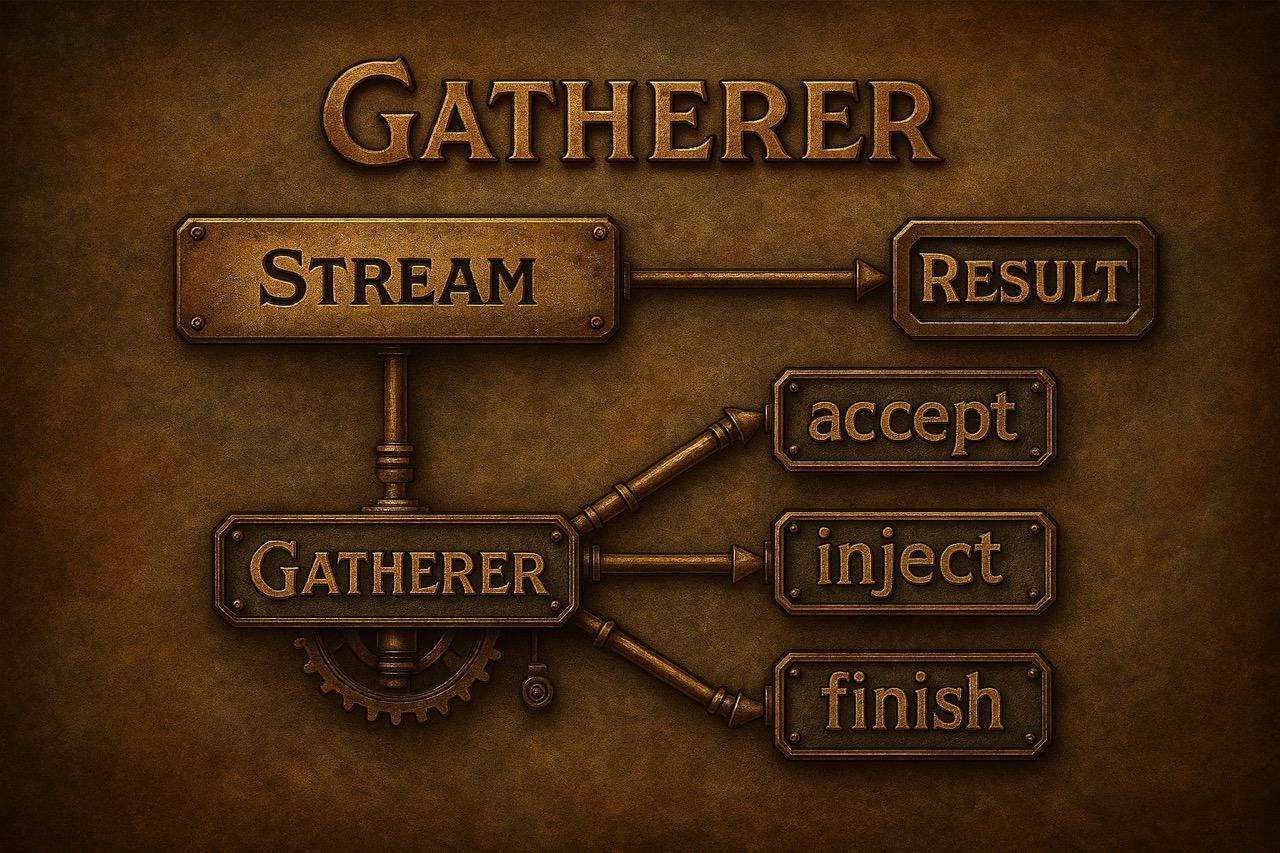
Since version 8, Java has introduced an elegant, functional approach to processing data sets with the Streams API. The terminal operation collect(…) represents the bridge from the stream to a targeted aggregation - in the form of lists, maps, strings or more complex data structures. Until Java 20 the processing was done Collector-Instances were regulated, which internally consisted of a supplier, an accumulator, a combiner and optionally a finisher. This model works well for simple accumulations but has noticeable limitations, particularly for complex, stateful, or conditional aggregations.
The introduction of the Stream API in Java marked a crucial step in the development of functional programming paradigms within the language. With Java 24, stream processing has been further consolidated and is now a central tool for declarative data processing Stream not about an alternative form of Collection, but rather an abstract concept that describes a potentially infinite sequence of data that is transformed and consumed through a pipeline of operations. While a Collection is a data structure that stores data, Stream is a carrier of a computing model: It does not store any data but instead allows the description of data flows.